
June 12, 2019
From WikiPedia:
A recurrent neural network (RNN) is a class of artificial neural network where connections between nodes form a directed graph along a temporal sequence. This allows it to exhibit temporal dynamic behavior.
Unlike feedforward neural networks, RNNs can use their internal state (memory) to process sequences of inputs. This makes them applicable to tasks such as unsegmented, connected handwriting recognition or speech recognition.
From The Unreasonable Effectiveness of Recurrent Neural Networks
Sequences. Depending on your background you might be wondering: What makes Recurrent Networks so special? A glaring limitation of Vanilla Neural Networks (and also Convolutional Networks) is that their API is too constrained: they accept a fixed-sized vector as input (e.g. an image) and produce a fixed-sized vector as output (e.g. probabilities of different classes). Not only that: These models perform this mapping using a fixed amount of computational steps (e.g. the number of layers in the model). The core reason that recurrent nets are more exciting is that they allow us to operate over sequences of vectors: Sequences in the input, the output, or in the most general case both. A few examples may make this more concrete:
From Understanding LSTM…
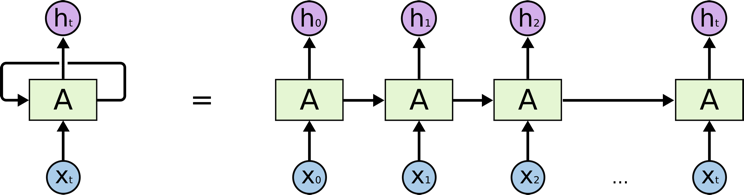
Here’s an overall look at what an RNN architecture looks like:

If we unroll the layer into its pieces we get:
Problems with RNNs
As you can imagine, as you add more and more items to the sequences, there are issues that occur based on the way weights are updated.
Exploding and Vanishing Gradients
From The curious case of the vanishing & exploding gradient:
These problems arise during training of a deep network when the gradients are being propagated back in time all the way to the initial layer. The gradients coming from the deeper layers have to go through continuous matrix multiplications because of the the chain rule, and as they approach the earlier layers, if they have small values (<1), they shrink exponentially until they vanish and make it impossible for the model to learn , this is the vanishing gradient problem. While on the other hand if they have large values (>1) they get larger and eventually blow up and crash the model, this is the exploding gradient problem.
Solutions to Exploding/Vanishing Gradients
From Wikipedia
Long short-term memory (LSTM) is an artificial recurrent neural network (RNN) architecture used in the field of deep learning. Unlike standard feedforward neural networks, LSTM has feedback connections that make it a “general purpose computer” (that is, it can compute anything that a Turing machine can). It can not only process single data points (such as images), but also entire sequences of data (such as speech or video). For example, LSTM is applicable to tasks such as unsegmented, connected handwriting recognition or speech recognition. Bloomberg Business Week wrote: “These powers make LSTM arguably the most commercial AI achievement, used for everything from predicting diseases to composing music.”
A common LSTM unit is composed of a cell, an input gate, an output gate and a forget gate. The cell remembers values over arbitrary time intervals and the three gates regulate the flow of information into and out of the cell.
History
LSTM was proposed in 1997 by Sepp Hochreiter and Jürgen Schmidhuber. By introducing Constant Error Carousel (CEC) units, LSTM deals with the exploding and vanishing gradient problems. The initial version of LSTM block included cells, input and output gates.
In 1999, Felix Gers and his advisor Jürgen Schmidhuber and Fred Cummins introduced the forget gate (also called “keep gate”) into LSTM architecture, enabling the LSTM to reset its own state.
In 2000, Gers & Schmidhuber & Cummins added peephole connections (connections from the cell to the gates) into the architecture. Additionally, the output activation function was omitted.
In 2014, Kyunghyun Cho et al. put forward a simplified variant called Gated recurrent unit (GRU).
Among other successes, LSTM achieved record results in natural language text compression, unsegmented connected handwriting recognition and won the ICDAR handwriting competition (2009). LSTM networks were a major component of a network that achieved a record 17.7% phoneme error rate on the classic TIMIT natural speech dataset (2013).
As of 2016, major technology companies including Google, Apple, and Microsoft were using LSTM as fundamental components in new products. For example, Google used LSTM for speech recognition on the smartphone, for the smart assistant Allo and for Google Translate. Apple uses LSTM for the “Quicktype” function on the iPhone and for Siri. Amazon uses LSTM for Amazon Alexa.
Code Example
!pip install numpy==1.16.1
Collecting numpy==1.16.1
[?25l Downloading https://files.pythonhosted.org/packages/f5/bf/4981bcbee43934f0adb8f764a1e70ab0ee5a448f6505bd04a87a2fda2a8b/numpy-1.16.1-cp36-cp36m-manylinux1_x86_64.whl (17.3MB)
[K |████████████████████████████████| 17.3MB 4.6MB/s
[31mERROR: datascience 0.10.6 has requirement folium==0.2.1, but you'll have folium 0.8.3 which is incompatible.[0m
[31mERROR: albumentations 0.1.12 has requirement imgaug<0.2.7,>=0.2.5, but you'll have imgaug 0.2.9 which is incompatible.[0m
[?25hInstalling collected packages: numpy
Found existing installation: numpy 1.16.4
Uninstalling numpy-1.16.4:
Successfully uninstalled numpy-1.16.4
Successfully installed numpy-1.16.1
'''
#Train a recurrent convolutional network on the IMDB sentiment classification task.
Gets to 0.8498 test accuracy after 2 epochs. 41 s/epoch on K520 GPU.
'''
from __future__ import print_function
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.layers import Embedding
from keras.layers import LSTM
from keras.layers import Conv1D, MaxPooling1D
from keras.datasets import imdb
# Embedding
max_features = 20000
maxlen = 100
embedding_size = 128
# Convolution
kernel_size = 5
filters = 64
pool_size = 4
# LSTM
lstm_output_size = 70
# Training
batch_size = 30
epochs = 2
'''
Note:
batch_size is highly sensitive.
Only 2 epochs are needed as the dataset is very small.
'''
print('Loading data...')
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
print(len(x_train), 'train sequences')
print(len(x_test), 'test sequences')
Using TensorFlow backend.
Loading data...
Downloading data from https://s3.amazonaws.com/text-datasets/imdb.npz
17465344/17464789 [==============================] - 1s 0us/step
25000 train sequences
25000 test sequences
print('Pad sequences (samples x time)')
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)
print('Build model...')
model = Sequential()
model.add(Embedding(max_features, embedding_size, input_length=maxlen))
model.add(Dropout(0.25))
model.add(Conv1D(filters,
kernel_size,
padding='valid',
activation='relu',
strides=1))
model.add(MaxPooling1D(pool_size=pool_size))
model.add(LSTM(lstm_output_size))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
print('Train...')
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_test, y_test))
score, acc = model.evaluate(x_test, y_test, batch_size=batch_size)
print('Test score:', score)
print('Test accuracy:', acc)
Pad sequences (samples x time)
x_train shape: (25000, 100)
x_test shape: (25000, 100)
Build model...
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/keras/backend/tensorflow_backend.py:3445: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version.
Instructions for updating:
Please use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`.
Train...
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
Train on 25000 samples, validate on 25000 samples
Epoch 1/2
25000/25000 [==============================] - 94s 4ms/step - loss: 0.3863 - acc: 0.8195 - val_loss: 0.3441 - val_acc: 0.8470
Epoch 2/2
25000/25000 [==============================] - 90s 4ms/step - loss: 0.1984 - acc: 0.9246 - val_loss: 0.3437 - val_acc: 0.8564
25000/25000 [==============================] - 10s 402us/step
Test score: 0.3437229507625103
Test accuracy: 0.8564399932861329